
Streaming Systems - Chapter 8 : Looking Forward: Toward Robust Streaming SQL
핵심 개념 및 SQL 확장
- SQL에 견고한 스트리밍을 지원하기 위한 핵심은 시간에 따라 변화하는 관계(Time-Varying Relations, TVRs)를 사용하는 것.
- SQL에 사용되는 방법을 그대로 적용할 수도 있지만, 이것이 실용적이지 않은 케이스들이 있음: table과 stream 두가지를 다 다룰 수 있어야 함.
- 시간, 특히 event time에 대해서도 고려를 해야 함. : timestamp, windowing, triggering에 대한 고려 필요.
Stream and Table Selection
시간에 따라 변화하는 관계(TVR)는 테이블(Table) 또는 스트림(Stream)의 두 가지 방식으로 물리적으로 표현.
- TABLE 키워드: 특정 시점의 스냅샷 뷰를 반환합니다.
- STREAM 키워드: 시간 경과에 따른 데이터의 변화를 이벤트 단위로 캡처한 뷰를 반환합니다.
TABLE과 STREAM중 무엇을 선택하는 것이 좋은가? - 좋은 기본값: 명시적인 키워드를 제공하지 않을 때 시스템이 채택해야 할 기본 동작에 따라.
- 모든 입력이 테이블일 경우: 출력은 기본적으로 테이블. 이는 기존 SQL 쿼리의 동작과 일치합니다.
- 하나라도 입력이 스트림일 경우: 출력은 기본적으로 스트림.
Table이나 Stream과 같은 TVR의 물리적인 표현은 TVR을 (사용자가) 직접 보거나 특정 테이블/Stream으로 출력하려는 경우에만 필요하다.
테이블은 특정 시점만 포함하거나, 스트림은 기록 중 일부만 포함하게 됨. (리소스 절감을 위한 trade-off) 쿼리의 중간 단게에서 TVR을 이런식으로 랜더링하면 정보 손실/불필요한 오버헤드가 발생함. 스트리밍 SQL이 강력해지려면 이러한 손실이나 불필요한 변환 없이 데이터를 최대한 완전하게 다루는 것이 중요.
시간 관련 연산자 (Temporal Operators)
견고한 순서 불일치 처리(out-of-order processing)의 기반은 이벤트 시간(event-time timestamp) SQL의 세계에서 event time은 단순히 하나의 column. source data 자체에 있음.
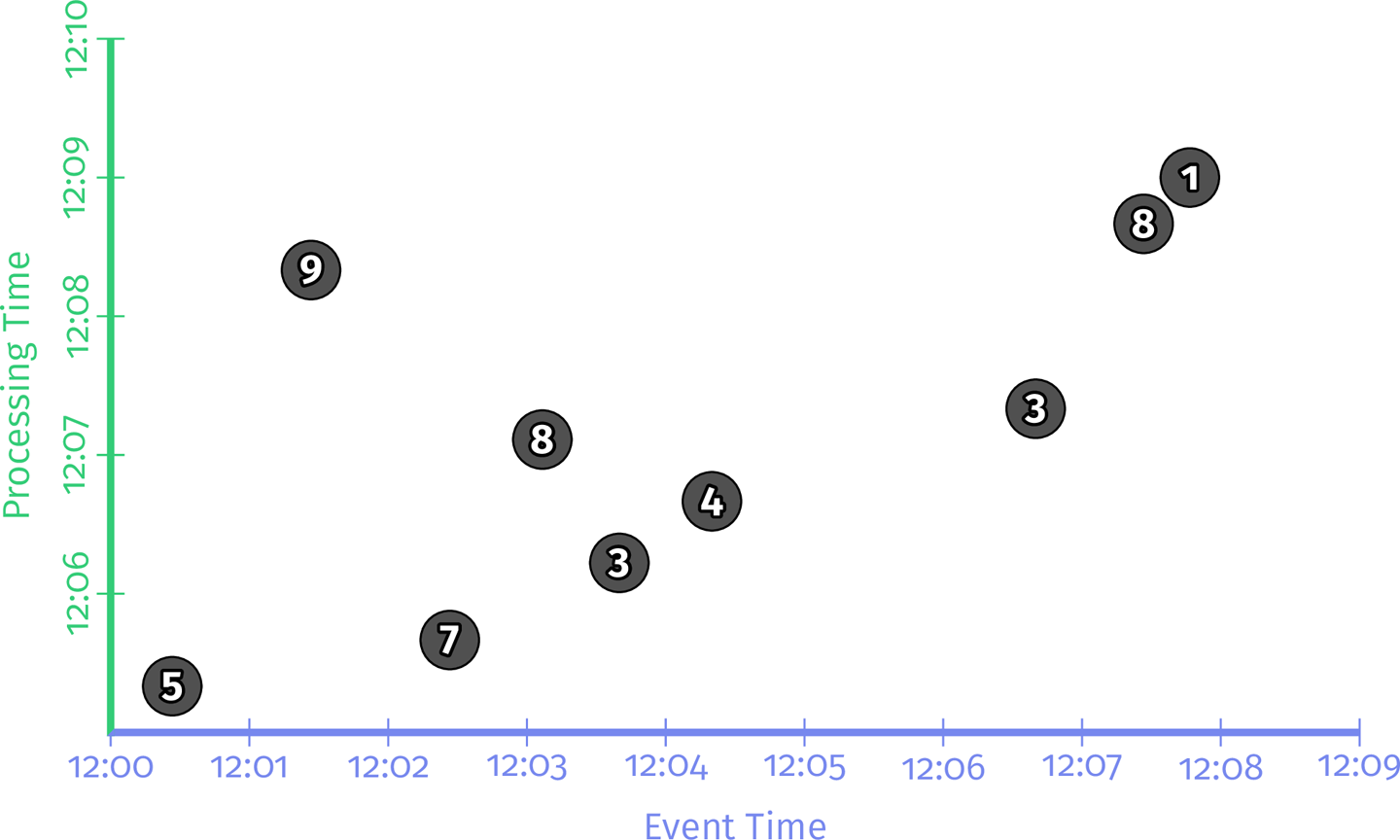 앞에서 계속 사용한 시간별 점수 그림을 SQL 테이블로 나타내면 아래와 같이 표현됨:
앞에서 계속 사용한 시간별 점수 그림을 SQL 테이블로 나타내면 아래와 같이 표현됨:
12:10> SELECT TABLE *, Sys.MTime as ProcTime
FROM UserScores ORDER BY EventTime;
------------------------------------------------
| Name | Team | Score | EventTime | ProcTime |
------------------------------------------------
| Julie | TeamX | 5 | 12:00:26 | 12:05:19 |
| Frank | TeamX | 9 | 12:01:26 | 12:08:19 |
| Ed | TeamX | 7 | 12:02:26 | 12:05:39 |
| Julie | TeamX | 8 | 12:03:06 | 12:07:06 |
| Amy | TeamX | 3 | 12:03:39 | 12:06:13 |
| Fred | TeamX | 4 | 12:04:19 | 12:06:39 |
| Naomi | TeamX | 3 | 12:06:39 | 12:07:19 |
| Becky | TeamX | 8 | 12:07:26 | 12:08:39 |
| Naomi | TeamX | 1 | 12:07:46 | 12:09:00 |
------------------------------------------------
- SQL로 랜더링함으로서 9개의 점수가 7명의 user에 의해 났다거나, 이들이 모든 같은 팀이라든가의 정보 확인 가능.
- 각 기록에 대해 event time과 processing time을 모두 보여줌.
- 간단하게 다른 방법으로 볼 수 있음 (ex. ORDER BY 키워드로 processing time 기준으로 정렬 가능)
- 부분적으로 (특정 시점만 보여주니까) 충실한 View라고 할 수 있음.
만약 SQL로 시점에 따른 변화를 그려주려면 n개의 table이 나와야 함. (너무 많다.) 이에 비해 stream은 비교적 심플하게 표현 가능.
12:00> SELECT STREAM Score, EventTime, Sys.MTime as ProcTime FROM UserScores;
--------------------------------
| Score | EventTime | ProcTime |
--------------------------------
| 5 | 12:00:26 | 12:05:19 |
| 7 | 12:02:26 | 12:05:39 |
| 3 | 12:03:39 | 12:06:13 |
| 4 | 12:04:19 | 12:06:39 |
| 8 | 12:03:06 | 12:07:06 |
| 3 | 12:06:39 | 12:07:19 |
| 9 | 12:01:26 | 12:08:19 |
| 8 | 12:07:26 | 12:08:39 |
| 1 | 12:07:46 | 12:09:00 |
........ [12:00, 12:10] ........
- 맨 아래의 trailing footer (…….. [12:00, 12:10] ……..)가 해당되는 기간을 나타냄.
- stream이 더 데이터가 들어오는걸 기다리고 있음에 유의.
이제 이 단순한 stream을 조작하기 시작하면 더 재밌어짐.
PCollection<String> raw = IO.read(...);
PCollection<KV<Team, Integer>> input = raw.apply(new ParseFn());
PCollection<KV<Team, Integer>> totals =
input.apply(Sum.integersPerKey()); // input을 합치고 있음.
http://www.streamingbook.net/fig/8-7
이 예시에서 우리의 data가 bounded data기 때문에 전통적인 batch와 다를바 없고, table과 stream의 형태가 매우 유사함.
12:10> SELECT TABLE SUM(Score) as Total, MAX(EventTime),
MAX(Sys.MTime) as "MAX(ProcTime)" FROM UserScores GROUP BY Team;
------------------------------------------
| Total | MAX(EventTime) | MAX(ProcTime) |
------------------------------------------
| 48 | 12:07:46 | 12:09:00 |
------------------------------------------
12:00> SELECT STREAM SUM(Score) as Total, MAX(EventTime),
MAX(Sys.MTime) as "MAX(ProcTime)" FROM UserScores GROUP BY Team;
------------------------------------------
| Total | MAX(EventTime) | MAX(ProcTime) |
------------------------------------------
| 48 | 12:07:46 | 12:09:00 |
------ [12:00, 12:10] END-OF-STREAM ------
윈도잉 (Windowing)
PCollection<String> raw = IO.read(...);
PCollection<KV<Team, Integer>> input = raw.apply(new ParseFn());
PCollection<KV<Team, Integer>> totals = input
.apply(Window.into(FixedWindows.of(TWO_MINUTES))) // 요부분이 추가됨. 2분 간격으로 나눈 것.
.apply(Sum.integersPerKey());
http://www.streamingbook.net/fig/8-8
8-7 대비 달라진 것: 하나의 sum이 아니라 2분 간격의 window로 나뉘어서 4개의 윈도우에 각각 sum이 존재하게 됨. GROUP BY를 사용하거나, built-in windowing operation을 사용함으로서 이런식으로 윈도우를 나눌 수 있음.
ad hoc windowing
group by를 사용해서 아래와 같이 표현 가능:
12:10> SELECT TABLE SUM(Score) as Total,
"[" || EventTime / INTERVAL '2' MINUTES || ", " ||
(EventTime / INTERVAL '2' MINUTES) + INTERVAL '2' MINUTES ||
")" as Window,
MAX(Sys.MTime) as "MAX(ProcTime)"
FROM UserScores
GROUP BY Team, EventTime / INTERVAL '2' MINUTES;
------------------------------------------------
| Total | Window | MAX(ProcTime) |
------------------------------------------------
| 14 | [12:00:00, 12:02:00) | 12:08:19 |
| 18 | [12:02:00, 12:04:00) | 12:07:06 |
| 4 | [12:04:00, 12:06:00) | 12:06:39 |
| 12 | [12:06:00, 12:08:00) | 12:09:00 |
------------------------------------------------
명시적 windowing
Apache Calciter와 같이 windowing statement가 지원하는 경우도 있음:
12:10> SELECT TABLE SUM(Score) as Total,
TUMBLE(EventTime, INTERVAL '2' MINUTES) as Window,
MAX(Sys.MTime) as 'MAX(ProcTime)'
FROM UserScores
GROUP BY Team, TUMBLE(EventTime, INTERVAL '2' MINUTES);
------------------------------------------------
| Total | Window | MAX(ProcTime) |
------------------------------------------------
| 14 | [12:00:00, 12:02:00) | 12:08:19 |
| 18 | [12:02:00, 12:04:00) | 12:07:06 |
| 4 | [12:04:00, 12:06:00) | 12:06:39 |
| 12 | [12:06:00, 12:08:00) | 12:09:00 |
------------------------------------------------
group by로도 충분한데, 명시적인 windowing 생성을 지원하는 이유:
- 윈도우 계산의 자동화: 직접 윈도우 계산을 수행할 필요 없이, 너비 / 슬라이드와 같은 기본 파라미터를 지정하여 결과를 얻기 쉽다.
- 복잡하고 동적인 그룹화를 간결하게 표현: 세션 윈도우, self join 등등…
워터마크 (Watermarks) / 트리거 (Triggering)
windowing 까지는 data를 table처럼 소비하면서 기존의 batch나 관계형 데이터처럼 취급함. 하지만 Stream으로 된 data를 받아들이려면 ‘processing time 중 언제 결과를 materialize 해야 하는가’하는 질문이 떠오르게 됨. : 기존과 마찬가지로 트리거와 워터마크가 정답임.
A SQL-ish default: per-record trigger
데이터가 도착할 때마다 trigger 하는 경우의 장점:
- 단순함: 이해하기 편함. materialized view는 이런식으로 동작해왔음
- 정확도: 원본 TVR이 가진 시간적 정보/변화를 스트림이 완벽하게 보존/표현 (앞선 table이 partial-fidelity 였던 것과 대조) - 뒤에 나올 다른 trigger들도 fidelity는 희생하게 됨.
단점:
-
비용
- Trigger는 grouping 다음에 오게되는데, grouping은 특성상 data flow의 cardinality를 줄이고, triggering은 특성상 데이터의 빈도를 줄여 줌. -> 비용 절감.
- 비용이 중요하지 않다면, per-record trigger를 사용할 때의 단순함+정확도의 이점이 완벽하지 않은 트리거를 사용하는 인지적 복잡성보다 크다.
http://www.streamingbook.net/fig/8-9
부작용: data가 안정화 되자마자 트리거에 의해 다시 바뀌게 되므로 안정화 되는(brought to rest)효과를 억제하게 됨. 그리고 매우 시끄러움(chatty). 우리가 큰 스케일의 애플리케이션을 만들고 있다면, 모든 upstream에서의 기록 발생때마다 downstream에서 계산을 하는 비용을 지불하고 싶지는 않을 것.
Watermark triggers
http://www.streamingbook.net/fig/8-10 (늦게 오는 숫자는 SUM에 숫자가 바뀌지만 그 아래 STREAM에는 반영되지 않음에 유의 -> 데이터 유실)
늦게 도착한 data에 대해서는 즉시lateFiring 함으로서 보완할 수 있음. http://www.streamingbook.net/fig/8-11
이 때 2개의 컬럼을 추가하면 유용하다.
- Sys.EmitTiming: watermark 대비한 타이밍 (on-time / late)
- Sys.EmitIndex: revisions for a given row/window
12:00> SELECT STREAM SUM(Score) as Total,
TUMBLE(EventTime, INTERVAL '2' MINUTES) as Window,
CURRENT_TIMESTAMP as EmitTime,
Sys.EmitTiming, Sys.EmitIndex
FROM UserScores
GROUP BY Team, TUMBLE(EventTime, INTERVAL '2' MINUTES)
EMIT WHEN WATERMARK PAST WINDOW_END(Window)
AND THEN AFTER 0 SECONDS;
----------------------------------------------------------------------------
| Total | Window | EmitTime | Sys.EmitTiming | Sys.EmitIndex |
----------------------------------------------------------------------------
| 5 | [12:00:00, 12:02:00) | 12:06:00 | on-time | 0 |
| 18 | [12:02:00, 12:04:00) | 12:07:30 | on-time | 0 |
| 4 | [12:04:00, 12:06:00) | 12:07:41 | on-time | 0 |
| 14 | [12:00:00, 12:02:00) | 12:08:19 | late | 1 |
| 12 | [12:06:00, 12:08:00) | 12:09:22 | on-time | 0 |
.............................. [12:00, 12:10] ..............................
(밑에서 두번째 열 보기)
Repeated delay triggers
데이터가 도착한 후 프로세싱 타임 상 1분 후에 해당 window trigger 하기
- 로드를 고르게 분산하는데 도움이 됨.
- Watermark가 필요하지 않음
http://www.streamingbook.net/fig/8-12 각 윈도우에 첫번째 데이터가 도착하고 1분 후 트리거 되어서 그 사이에 도착한 데이터를 함께 처리함. (이거때문데 per-record보단 덜 시끄러움) 트리거 완료 후 데이터가 도착하면 다시 그 이후로 1분 기다렸다가 트리거. 비용과 적시성(timeliness) 사이의 밸런스를 잡음.
Data-driven triggers
score > 10과 같이 데이터를 보고 trigger 하는 것은 결국 per-record trigger를 매번 하고 해당 조건을 만족할때만 downstream으로 보내주겠다는 것과 같다. 따라서 명시적으로 있을 필요가 없다.
Accumulation
누적 방식은 단일 윈도우에 대해 여러 번 결과가 구체화될 때 결과들의 관계를 정의
지금까지 본 것: Accumulation 모드. http://www.streamingbook.net/fig/8-13 단점: Over Counting
Accumulation & Retraction: 더해서 내보내면서 이전단계를 빼주는 것. -> Down stream에서 over counting을 신경쓰지 않아도 됨. http://www.streamingbook.net/fig/8-14
12:00> SELECT STREAM SUM(Score) as Total,
SESSION(EventTime, INTERVAL '1' MINUTE) as Window,
CURRENT_TIMESTAMP as EmitTime,
Sys.Undo as Undo
FROM UserScoresForSessions
GROUP BY Team, SESSION(EventTime, INTERVAL '1' MINUTE);
--------------------------------------------------
| Total | Window | EmitTime | Undo |
--------------------------------------------------
| 5 | [12:00:26, 12:01:26) | 12:05:19 | |
| 7 | [12:02:26, 12:03:26) | 12:05:39 | |
| 3 | [12:03:39, 12:04:39) | 12:06:13 | |
| 3 | [12:03:39, 12:04:39) | 12:06:46 | undo |
| 7 | [12:03:39, 12:05:19) | 12:06:46 | |
| 3 | [12:06:39, 12:07:39) | 12:07:19 | |
| 7 | [12:02:26, 12:03:26) | 12:07:33 | undo |
| 7 | [12:03:39, 12:05:19) | 12:07:33 | undo |
| 22 | [12:02:26, 12:05:19) | 12:07:33 | |
| 3 | [12:06:39, 12:07:39) | 12:08:13 | undo |
| 11 | [12:06:39, 12:08:26) | 12:08:13 | |
| 5 | [12:00:26, 12:01:26) | 12:08:19 | undo |
| 22 | [12:02:26, 12:05:19) | 12:08:19 | undo |
| 36 | [12:00:26, 12:05:19) | 12:08:19 | |
| 11 | [12:06:39, 12:08:26) | 12:09:00 | undo |
| 12 | [12:06:39, 12:08:46) | 12:09:00 | |
................. [12:00, 12:10] .................
다운스트림에서 하나의 그룹으로 단순하게 high-volumn 더하는 등의 특수한 유즈케이스가 아니라면 discarding 모드는 복잡하고 에러를 만들기 쉬움. (기본적으로 비추천)