
한국 서비스를 기반으로 시스템 디자인 공부하기 – MY BOX
시스템 디자인을 공부하다 보면 대부분의 자료가 영어로 작성되어 있고, 주로 영어권 서비스를 대상으로 하고 있습니다. 이 때문에 한국 개발자들은 시스템 디자인 자체뿐만 아니라 해당 서비스에 대한 이해도 함께 필요하게 되어 학습 과정이 더 복잡해지는 경우가 많습니다. 이를 해결하기 위해, 한국의 대표적인 서비스를 기반으로 시스템 디자인을 공부하고, 유사한 해외 서비스를 함께 연결해 보려 합니다. 다른 글 보기
이번에 다룰 서비스는 ‘MY BOX’입니다. MY BOX는 네이버에서 제공하는 클라우드 저장소 서비스로, 사용자에게 사진, 동영상, 문서 등 다양한 파일을 안전하게 보관하고 관리할 수 있는 환경을 제공합니다. PC와 모바일 앱을 통해 손쉽게 접근할 수 있으며, 자동 백업, 폴더 공유, 미디어 콘텐츠 바로보기 등 사용자 편의를 고려한 다양한 기능을 갖추고 있습니다. 여기서는 MY BOX의 많은 기능 중에서도 가장 코어 기능이라고 할 수 있는, 파일을 업로드하고 저장하며 이를 조회 및 다운로드하는 기능에 대해 시스템 디자인을 해보겠습니다.
MY BOX 파일 업로드 / 다운로드의 기본 흐름 따라가기
기본적인 파일 업로드 / 다운로드 흐름을 따라가보도록 하겠습니다.
먼저, 보관할 파일을 업로드합니다. 사진 올리기 메뉴를 가면
기기 로컬에 있는 파일들을 선택할 수 있습니다. 업로드할 파일을 선택한 후 진행합니다.
업로드 상태로 가면 잠깐의 올리기 준비중을 거친 후
업로드가 됩니다. 업로드가 완료되면 업로드된 시각이 내역에 표시됩니다.
반대로 다운로드를 하려는 경우는, 먼저 MY BOX에 저장되어있는 파일들 중 다운로드 하고자 하는 파일을 선택합니다.
다운로드를 진행하면 잠시 대기중이 되었다가
조금 기다리면 다운로드가 완료됩니다. 다운로드가 완료된 시각이 표시됩니다.
Requirements
시스템을 설계하려면 먼저 요구사항을 명확히 정리하는 것이 중요합니다. 시스템이 가져야 할 핵심 기능을 정의하고, 트래픽 증가나 동시성 문제에 대한 비기능 요구사항도 함께 고려해야 합니다. 앞서 정리한 티켓 예매 흐름을 바탕으로, 시스템 설계를 위한 요구사항을 분석해 보겠습니다.
Functional Requirements
MY BOX와 클라우드 저장소 서비스가 기본적으로 제공해야 할 기능은 다음과 같습니다.
- 사용자는 파일을 업로드할 수 있습니다.
- 사용자는 파일을 다운로드 할 수 있습니다.
- 사용자는 PC와 모바일에서 서비스를 이용할 수 있습니다.
이 글에서는 기본적인 업로드/다운로드 흐름에 집중하기 위해 아래 기능들은 다루지 않습니다.
- Blob 저장소 운영
- 공유 기능
- 온라인 스트리밍 기능
- 구매 상품별 다른 파일 사이즈 지원
- 인물 분류 기능 등
Non-Functional Requirements
- 파일을 보는데 있어서 데이터 일관성(consistency)보다는 가용성(availability)이 더 중요할 것으로 가정합니다. 지금 업로드한 파일이 바로 보이지 않는다고 비지니스에 문제가 생기는 앱이 아니기 때문입니다. 전체 시스템의 가용성을 우선순위로 두는 대신 Eventual Consistency를 추구하려고 합니다.
- 대신, Data Integrity는 중요합니다. 데이터가 깨지거나 바뀌어서는 안됩니다.
- 파일 업로드/다운로드는 너무 느려서는 안됩니다. (Latency)
- 동영상과 같은 큰 파일도 지원해야 합니다(10GB~50GB). 이를 위해서 업로드/다운로드를 일시정지 할 수 있어야 합니다.
Core Entities
예상되는 핵심 엔티티들을 정의합니다. 우선 떠오르는 엔티티들을 간단히 정리하고, 이후 실제 설계 과정에서 필요에 따라 확장하거나 조정할 수 있습니다. 각 엔티티의 ID 필드는 생략합니다.
- User
- 사용자
- File Metadata
- FileName, dateUploaded, FileSize, FileUrl, UserId
- File
- File 자체
High level Design
시스템 디자인 인터뷰에서는 제한된 시간 내에 전체적인 아키텍처를 설계해야 합니다. 일반적으로 1시간 이내의 인터뷰에서, 소개나 마지막 질의응답, 그리고 Behavior Questions(행동 관련 질문) 등을 제외하면 실제 설계에 주어진 시간은 약 30~40분 정도입니다.
이 짧은 시간 안에 완벽한 이상적인 디자인을 만드는 것은 현실적으로 어렵기 때문에, High-Level Design 단계에서는 핵심 컴포넌트와 API 설계에 집중하고, 이후 Low-Level Design에서 세부적인 최적화를 논의하자고 합의를 하는 것이 좋을 것 같습니다.
사용자가 파일을 업로드하는 기능
먼저 사용자가 파일을 업로드하는 기능을 생각해 보겠습니다. 여기서는 100MB 이하의 작은 파일일 때를 먼저 가정해보겠습니다.
PC든 Mobile이든 사용자가 파일을 선택해서 업로드를 시작하면, 클라이언트는 POST /files API를 호출합니다. multipart/form-data 형식으로 파일과 메타데이터를 함께 전송하고, File Service는 요청을 파싱하여 S3와 같은 객체 스토리지(object storage)에 저장한 뒤, 이 파일의 url과 메타데이터를 File metadata DB에 보관합니다.
MY BOX에서 파일을 업로드하고 나면 파일 리스트들을 볼 수 있는데, 이 때 각 파일의 섬네일(thumbnail)이 같이 뜨는 것을 볼 수 있습니다. 업로드를 하면서 이 섬네일도 함께 생성하는 것이 합리적일 것으로 보입니다. 다만, 이것은 디자인적인 측면일뿐 사용에 영향을 끼치지는 않는 것이 맞으므로, sync로 생성하지는 않는 것이 좋을 것 같습니다. 별도 작업 큐와 Thumbnail Service를 두기로 하겠습니다.
File Service는 파일을 업로드 하면서 섬네일 생성을 위한 큐에 요청을 보냅니다. Thumbnail Service는 Queue에서 요청을 꺼내 섬네일을 생성한 후 S3에 저장합니다. 그리고 이 S3 url을 metadata DB에 저장합니다. 우리의 file metadata entity에 thumbnailUrl 필드가 추가되어야겠네요.
사용자가 파일을 다운로드하는 기능
이제 다운로드하는 흐름을 생각해보도록 하겠습니다. 유저가 다운로드하기 위해서는 먼저 파일 리스트를 볼 필요가 있습니다. GET /files API를 호출하면 업로드한 파일의 리스트를 볼 수 있게 합니다. GET /files?page=1&pageSize=20와 같이 페이징을 하는 것이 합리적일 것입니다. GET API는 fileId와 함께 리스트에 표시할 기본적인 메타데이터(섬네일, 업로드 일시와 용량 등)를 리턴합니다.
이 파일 리스트 중 다운로드할 파일을 선택하면 GET /files/{fileId} API가 호출됩니다. File Service는 fileId로 메타데이터를 조회해 객체 저장소 내의 실제 위치를 확인하고, 해당 파일을 직접 읽어 클라이언트에게 바이너리 데이터로 응답합니다. 다운로드 대상 파일은 스트리밍 방식으로 전송합니다.
스트리밍 방식은 전체 파일을 한 번에 메모리에 올리는 대신, 객체 저장소에서 데이터를 일정 크기로 읽어오면서 동시에 클라이언트에 전송하는 방식입니다. 이 방식은 메모리 사용을 최소화하고, 파일을 안정적으로 전송할 수 있다는 장점이 있습니다. 대부분의 백엔드 프레임워크는 이를 기본적으로 지원하며, 업로드의 경우는 보통 자동으로 스트리밍 방식이 사용됩니다. 다운로드는 간단한 코드만으로도 스트리밍 처리를 구현할 수 있습니다.
한국에서 많이 사용되는 Java/Spring 조합에서는 Java의 InputStream과 OutputStream 기능을 바탕으로, Spring이 제공하는 StreamUtils 등의 유틸리티를 활용할 수 있습니다. 예를 들어 StreamUtils.copy(in, out);와 같이, S3에서 서버로 데이터를 받아오는 스트림과 서버에서 클라이언트로 전송하는 스트림을 간단히 연결할 수 있습니다. Node.js 역시 자체 Stream 모듈을 제공하며, 유사한 방식으로 스트리밍 처리를 지원합니다.
예상되는 문제점들
대용량 파일의 업로드/다운로드시 부하 및 네트워크 유실 문제
MYBOX는 요금제에 따라 최대 10GB~50GB 크기의 파일을 보관할 수 있습니다. 이처럼 대용량 파일을 서버를 경유하여 업로드하는 경우, 서버는 10GB IN + 10GB OUT 트래픽을 동시에 감당해야 합니다. 여러 명의 사용자가 동시에 업로드를 시도하는 상황에서는, 서버의 네트워크 대역폭뿐 아니라 메모리, 디스크 버퍼, GC 등 시스템 리소스 전반에 부담이 발생할 수 있습니다.
또한 사용자가 대용량 파일을 업로드하거나 다운로드하는 도중에 네트워크가 끊기거나 브라우저를 닫는 상황이 발생할 수 있습니다. 이 경우 파일 전송을 처음부터 다시 시작해야 한다면, 사용자 경험에 심각한 불편을 초래하게 됩니다. 특히 모바일 환경이나 저속 네트워크 환경에서는 이러한 중단 가능성이 더욱 높아집니다.
대용량 파일들을 안정적으로 보관해야 하는 문제
대용량 파일이 빈번하게 업로드되고 장기간 보관되는 구조에서는 다양한 문제가 발생할 수 있습니다.
먼저, 저장소 측면에서 대용량 파일이 지속적으로 누적되면 저장 공간 부족, 비용 증가, 읽기/쓰기 지연 같은 리소스 부담이 커질 수 있습니다. 특히 자주 사용되지 않는 파일까지 고비용의 일반 스토리지에 계속 유지될 경우, 장기적으로 불필요한 저장 비용이 많이 발생할 수 있습니다.
또한 파일 자체만 저장한다고 끝나는 것이 아니라, 썸네일, 메타데이터, 접근 로그와 같은 부가 데이터들도 함께 관리되어야 하므로 이들 간의 정합성 문제가 발생할 수 있습니다. 예를 들어 파일은 업로드되었지만 메타데이터 반영이 누락되어 사용자에게 불완전한 정보가 노출될 수 있습니다.
이러한 상황에서 시스템은 반드시 데이터 무결성(Data Integrity)을 보장해야 합니다. 사용자가 업로드한 파일이 손상되거나 일부만 저장되는 일은 있어서는 안 됩니다. 반면, 모든 처리 결과를 완전히 정합하게 맞추려 할 경우, 처리 지연이 발생하고 전체 시스템의 가용성(Availability)이 떨어질 수 있습니다.
우리는 Integrity는 보장하면서도 Availability를 최대화하기 위해, 부가 데이터의 처리와 반영은 약간의 지연을 허용하는 Eventual Consistency 모델을 채택할 계획입니다.
사용자 체감 속도와 응답 시간 문제
업로드와 다운로드 과정이 느릴 경우 사용자의 이탈로 이어질 수 있습니다. 특히 대용량 파일의 경우, 파일 전송을 분할하고 병렬로 처리하는 등 latency를 줄이는 전략이 필요합니다. 단일 요청 처리 시간이 길어질수록 서버 자원에 부담이 커지고, 클라이언트에서도 UX 문제가 발생할 수 있으므로, 전송 중에도 프로그레스 UI 제공, 단계별 응답 처리, 스트리밍 응답 등을 통해 사용자 피드백을 확보해야 합니다.
Low-level Design
대용량 파일을 안정적으로 업로드하고 다운로드하는 문제는 많은 서비스에서 공통적으로 마주하는 과제입니다. 이를 해결하기 위한 기술은 다양하며, 오픈소스로도 구현되어 있습니다. 예를 들어 tus는 Resumable Upload를 위한 오픈소스 프로토콜로, 클라이언트가 업로드 도중 네트워크가 끊기더라도 중단된 지점부터 이어서 업로드할 수 있도록 설계되어 있습니다. HTTP 기반의 단순한 프로토콜이기 때문에 다양한 환경에서 쉽게 통합할 수 있으며, 여러 언어와 플랫폼에 대한 구현체를 제공합니다.
하지만 오픈소스를 사용한다로 끝나서는 글이 되지 않으므로 (^^;) 이 글에서는 tus를 도입하는 대신, AWS S3의 Multipart Upload와 HTTP Range 요청을 활용하여 클라이언트 주도의 업로드/다운로드 흐름을 직접 설계해보는 방향으로 접근하겠습니다.
대용량 업로드 지원하기
서버의 Bandwidth를 훼손하지 않으면서 더 빠르게 업로드하는 방법은 클라이언트에서 Storage로 바로 업로드할 수 있게 하는 것입니다. 파일을 서버를 통해서 업로드하지 않고, 최초 API 호출 때에는 업로드할 준비 및 Metadata의 저장만 한 후, 실제 업로드는 Client가 직접 처리합니다. AWS의 S3는 이럴 때 사용할 수 있는 방법으로 멀티파트 업로드를 지원합니다. 멀티파트 업로드(Multipart Upload)는 AWS S3에서 제공하는 대용량 파일 업로드 방식으로, 하나의 큰 파일을 여러 조각(Part)으로 나누어 따로따로 업로드한 뒤, 마지막에 이를 하나로 합쳐서 저장하는 방식입니다. 마치 10권짜리 백과사전을 택배로 보낼 때, 한 상자에 다 담기 어려우면 10개의 상자에 나눠서 보내고, 마지막에 수신자가 모두 도착한 상자를 모아 한 세트로 조립하는 방식과 같습니다. AWS에서는 100MB 이상의 객체인 경우 멀티파트 업로드 방식을 사용하길 추천하고 있어서 위 High level design에서 작은 파일의 기준을 100MB로 잡았습니다.
멀티파트 업로드에서 사용되는 용어들은 다음과 같습니다:
| 개념 | 설명 |
|---|---|
| Part | 전체 파일을 나눈 조각입니다. 각 조각은 최소 5MB 이상이어야 하며, 최대 10,000개까지 나눌 수 있습니다. |
| PartNumber | 조각의 번호입니다. 첫 번째 조각은 1번, 두 번째는 2번 등으로 순서가 정해집니다. |
| UploadId | 이 업로드 세션을 식별하는 고유한 ID입니다. 파일 전체를 다 올릴 때까지 이 값을 계속 사용합니다. |
| ETag | AWS가 각 Part를 업로드할 때 응답으로 돌려주는 고유한 해시값입니다. 최종 조립 시 꼭 필요합니다. |
| Complete | 모든 조각을 업로드한 뒤, “이제 다 올렸으니 하나로 합쳐주세요”라고 요청하는 단계입니다. |
그리고 업로드를 진행하는 동안 이 UploadId와 PartNumber등을 관리해야 합니다. 이를 클라이언트가 관리할 수도 있지만, 앞서 대용량 데이터, 네트워크 유실과 같은 문제점을 예상한 만큼 백엔드에서 관리하도록 하겠습니다. 이렇게 되면 클라이언트는 실제 파일 전송만 담당하고, 서버는 상태 관리와 전체 흐름 제어를 맡는 형태 운영됩니다.
그리고 이 데이터의 특성을 생각해보면 파일의 용량에 따라 저장해야하는 Upload와 PartNumber등의 갯수가 판이하게 다를 것임을 쉽게 예상할 수 있습니다. 그러므로 RDB를 사용한 기존 Metadata DB에 모든 필드를 추가하기보다는, 별도의 NoSQL DB를 운영하는 것이 바람직할 것 같습니다. 빠르게 읽고 쓰고, TTL로 자동 만료되고(업로드되다 만 파일도 AWS는 과금을 하기때문에 장기가 업로드하다 만 파일은 정리를 해줘야합니다.), 복잡한 쿼리 없이 key 기반으로 빠르게 접근할 수 있는 저장소이기 때문입니다. S3를 쓰고 있는 만큼 Dynamo DB를 사용하도록 하겠습니다. Dynamo DB는 AWS에서 제공하는 NoSQL로, 위에 언급한 조건을 모두 만족합니다. 그리고 기존 Metadata DB에는 이 Dynamo DB를 조회할 때 쓸 Key값 필드를 추가하도록 하겠습니다. 또한 업로드 상태가 장시간 지속될 것이 예상되므로 ‘상태’ 필드도 추가하는 것이 좋을 것 같습니다.
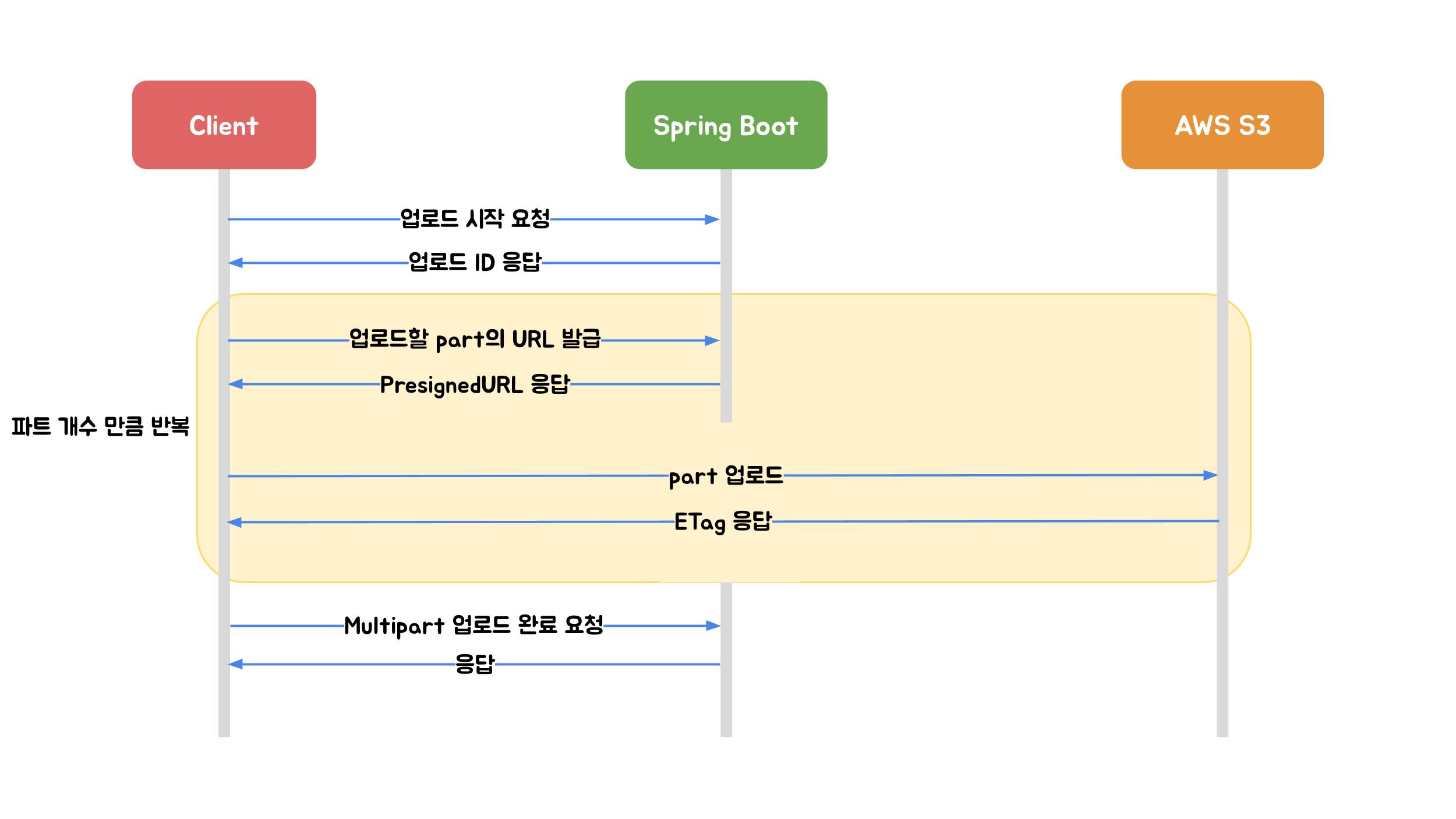
클라이언트는 POST /files/init-multipart API를 호출해 대용량 파일을 업로드 할 준비를 합니다. 업로드할 파일의 이름, 크기, 콘텐츠 타입 등의 정보를 서버에 전달합니다. 서버는 이 정보를 기반으로 S3에 Multipart Upload를 초기화하고, 업로드 상태를 관리할 수 있도록 업로드 ID와 파일 메타데이터를 저장합니다. 이후 클라이언트가 직접 S3에 파트를 업로드할 수 있도록 UploadId + pre-signed URL 목록을 응답으로 내려줍니다. 각 파트는 꼭 순서대로 업로드 될 필요가 없고, 동시에 업로드도 가능하기 때문에 빠르게 업로드할 수 있습니다. 우리가 앞서 봤던 ‘업로드 준비중’ 단계에서 이런 작업을 수행할 것으로 보입니다.
클라이언트는 이 pre-signed URL에 파일을 업로드합니다. 업로드를 완료하면 S3는 ETag를 돌려주는데, 이 Etag를 서버에 알려주면서 업로드가 완료했음을 알려야 합니다. POST /files/{fileId}/part-complete와 같은 식의 API를 만들어 body에 Etag를 담아 보내도록 하겠습니다. 서버는 클라이언트가 Etag를 저장하고 업로드 상태를 변경합니다. 만약 해당 file에 해당하는 모든 파트가 업로드 완료 상태라면 마지막으로 S3에 모든 업로드가 완료되었음을 알리고 S3는 파일을 합치게 됩니다. 이 때 요청에 Etag가 사용됩니다.
AWS의 멀티파트를 이용하면 서버를 거치지 않으므로 Bandwidth 문제를 해결하고, 파트별로 업로드를 하므로 병렬적으로, 순서 상관 없이 업로드할 수 있으며 일시정지나 네트워크 유실 후 재시작을 할 때에도 업로드가 끊겼던 파트만 다시 업로드를 할 수 있습니다. 더 자세한 업로드 과정은 우아한 기술 블로그의 Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 글을 참고하시길 추천합니다.
위에서 살짝 언급했지만, AWS는 업로드되다 만 파일도 요금을 과금하기 때문에 업로드가 장기간 끊겨서 사실상 중단된것으로 보인다면 S3에서도 정리해줘야 합니다. S3는 최초 Init 시점으로부터 일정 시간 이상 완료 처리가 안되면 Abort시키는 수명 주기 설정을 지원합니다. Dynamo DB에 설정된 TTL과 동일한 기간을 설정해주면 우리 서버에서 해당 업로드 정보를 삭제함과 동시에 S3에서도 정리되게 할 수 있습니다. 또한 주기적으로 이렇게 오랫동안 완료가 안되고 있는 파일들을 확인하여, metadata DB에서도 status를 abort로 변경해줘야 하겠습니다.
대용량 다운로드 지원하기
대용량의 다운로드도 업로드와 비슷하게 서버를 통하지 않는 방법을 지원합니다. 클라이언트가 S3의 pre-signed URL을 통해 직접 다운로드하되, HTTP Range 요청을 활용하여 중단된 위치에서 이어받을 수 있도록 할 수 있습니다.
HTTP Range 요청은 클라이언트가 “파일의 특정 바이트 범위만 내려주세요”라고 요청할 수 있는 기능입니다. 예를 들어, Range: bytes=1000000-2000000와 같은 요청을 보내면, S3는 해당 범위의 데이터만 내려줍니다. 이 방식은 대용량 다운로드 중 네트워크가 끊겼을 때, 처음부터 다시 받지 않고 이어받을 수 있도록 해주며, 동시에 병렬 다운로드도 가능하게 해줍니다.
클라이언트는 파일을 여러 청크(chunk)로 나누고, 각 청크에 대해 pre-signed URL + Range 헤더를 조합하여 병렬로 요청을 보낼 수 있습니다. 이렇게 하면 다운로드 속도도 빨라지고, 중간에 실패해도 실패한 청크만 다시 받으면 되므로 사용자 경험이 훨씬 좋아집니다. 위에서 봤던 ‘대기중’ 상태에서 이런 작업을 처리할 수 있을 것 같습니다.
이러한 상태 관리는 백엔드에서 관리할 것 없이 Client의 메모리~로컬 스토리지 선에서 관리하는 것으로 충분할 것으로 예상합니다. 다만 장기적으로 일시정지 했다가 다시 시작할 경우 pre-signed URL이 만료될 수 있는데, 이 경우, 클라이언트는 resume을 시작하기 전에 항상 GET /files/{fileId}/download-url API를 호출하여 새로운 pre-signed URL을 받아야 합니다. 이렇게 하면 S3에서 다시 인증 오류 없이 Range 요청을 보낼 수 있고, 이어받기(download resume)를 안정적으로 구현할 수 있습니다. 큰 용량의 파일이라면 중단 없이도 pre-signed URL이 만료될 수 있으므로 API의 응답 body에 expiredAt을 넣어서, expiredAt이 다가오는데도 다운로드가 끝나지 않았다면 추가적으로 url을 요청하여 끊기지 않게 설계할 수 있을 것 같습니다.
비용절약을 위한 Cold Storage 도입
대용량 파일을 장기 보관하는 구조에서는 저장소 비용이 무시할 수 없는 요소가 됩니다. 특히 큰 용량의 파일이 꾸준히 업로드되고, 사용자들이 그중 일부 파일만 자주 열람한다면 대부분의 파일이 장기간 “보관만 되는 상태”에 놓이게 됩니다. 이러한 파일은 조금 더 느리더라도, 저렴한 상품으로 옮기는 것이 합당한 선택일 것입니다.
우리는 현재 AWS S3를 파일 저장소로, DynamoDB를 상태 저장소로 사용하고 있으므로, AWS가 제공하는 Cold Storage 옵션인 S3 Intelligent-Tiering 또는 S3 Glacier를 도입하는 것이 가장 자연스러운 선택입니다. (AWS의 Storage Class 설명 페이지)
S3 Intelligent-Tiering은 AWS가 파일의 접근 패턴을 자동으로 모니터링하여, 자주 접근되는 파일은 Standard 클래스에, 접근이 드문 파일은 Infrequent Access 계층으로 자동 전환해주는 스토리지 클래스입니다. 복원 시간이 필요 없고 실시간 접근이 가능한 것이 장점이며, 파일 접근 패턴을 예측하기 어려운 경우에 적합합니다.
S3 Glacier는 더 극단적인 비용 절감을 원하는 경우 사용할 수 있는 Cold Storage 계층입니다. 저장 비용이 매우 낮은 대신, 다운로드를 위해 복원 요청이 필요하며 수 분에서 수 시간까지 대기 시간이 발생할 수 있습니다.
이러한 전환은 백엔드 서버에서 수동으로 옮길 필요 없이, AWS S3의 Lifecycle 설정을 통해 자동으로 적용할 수 있습니다. 예를 들어 ‘업로드 후 30일이 지난 파일은 Glacier로 이동’과 같은 규칙을 만들어두면, 객체 단위로 정책이 적용되어 운영 부담 없이도 스토리지 비용을 최적화할 수 있습니다.
다만 이러한 Cold Storage 계층으로의 전환은, 사용자가 해당 파일을 실제로 다시 다운로드하려고 할 때 수 분에서 수 시간의 복원 지연(latency)이 발생할 수 있다는 점을 고려해야 합니다. S3 Glacier Deep Archive와 같은 상품은 가장 저렴하지만 복원이 오래 걸리므로 사용자 경험을 크게 해칠 수 있습니다. 반면, S3 Glacier Instant는 Glacier 계열 중에서는 비싼 편이지만, 복원 지연이 ms~s 단위에 불과하므로, Availability를 중시하는 MY BOX와 같은 서비스에는 가장 합리적인 선택이 될 수 있습니다.
정리
대용량 파일을 안정적으로 업로드하고 다운로드하며, 장기 저장 비용까지 고려하는 시스템은 생각보다 다룰 요소가 많습니다. 이번 글에서는 MY BOX라는 파일 보관 서비스를 가정하고, 작고 단순한 파일부터 수십 GB에 이르는 대용량 파일까지 다양한 시나리오를 지원할 수 있도록 High level부터 Low level까지 설계를 정리해 보았습니다.
물론 여기서 끝은 아닙니다. 위에서 설계 범위로 제외한 공유 기능, 혹은 실시간 협업을 위한 버전 관리 시스템 등도 확장 주제로 이어질 수 있습니다. 그 외에도 보안이나 데이터 삭제 정책, 스토리지 이중화와 같은 주제도 훨씬 더 깊이 있게 설계해볼 수 있겠지요.
이번 글은 MY BOX를 중심으로 한 시스템 디자인 연습이었고, 기회가 된다면 다음엔 또 다른 주제로 돌아오겠습니다.