
트위터(현 X)가 진짜로 타임라인을 구성하는 방식
시스템 디자인을 공부하다보면 SNS에 글을 발행하고 이를 사람들의 타임라인에 뿌려주는 방법이 자주 등장합니다. 여러가지 기술이 언급되곤 하지만, 실제로 어떻게 구현되었는지 궁금하시진 않았나요? 이 글에서는 2020년에 발행된 Reducing search indexing latency to one second, 2023년에 발행된 Twitter’s Recommendation Algorithm 두 글의 내용을 따라가보면서 내가 올린 글을 친구가 타임라인에서 보게 되기까지 사용된 기술들을 살펴보겠습니다.
사용자가 포스트를 발행하면 이는 ingestion pipeline으로 전달되어 indexing이 일어납니다. 이 때 indexing이 빠르게 되어야 사용자는 발행된 포스트를 바로 확인할 수 있습니다. 이를 최대한 빠르게 하는데는 두가지 제약사항이 있었다고 합니다. 첫번째로는 사용자가 발행한 포스터의 내용이 모두 같은 속도/시점에 사용가능한게 아니라는 점입니다, 예를들어 단축된 url을 포함하고 있다면, 그 url의 원본 주소와 그 내용도 인덱싱을 해야 정확도가 올라갈 것입니다. 두번째는 포스트의 수신 순서가 생성 시간 순서가 아니라는 점입니다. 타임라인은 시간 역순으로 정렬되어있어야 하기 때문에 순서를 맞추기 위해 일정 시간동안 버퍼에 쌓아두었다가 정렬해서 indexing을 했다고 합니다. 이때문에 필연적으로 지연이 생겼던 것이죠. 이 문제들을 해결하고 빠르게 indexing을 하기 위해서 1.비동기 색인, 2.Skip list를 이용한 색인 두가지를 도입했다고 합니다.
색인(Indexing) 찍먹하기
이 색인을 할 때 사용되는 것이 Lucene이라는 라이브러리 입니다. full-text search를 위한 Java 라이브러리로, Elastic Search가 내부적으로 이를 사용하고 있다고 합니다. Lucene은 문서에서 단어를 찾아낼 수 있도록 하는 역색인(inverted index) 구조를 제공합니다. 이 역색인은 단어: [단어를 포함하고 있는 document의 id list]를 할 수 있게 합니다. 예를들어
document 1:
서울특별시발 토론토행
5월 5일 (월)
편도 · 성인 1명
오전 9:35 – 오전 9:55
대한항공 · 직항 · ICN–YYZ
₩1,137k
document 2:
서울특별시발 토론토행
5월 5일 (월)
편도 · 성인 1명
오후 7:05 – 오후 7:30
에어캐나다 · 직항 · ICN–YYZ
₩1,228k
두개의 문서가 있다고 치면, 우리의 역색인은
서울특별시: [1, 2]
토론토: [1, 2]
대한항공: [1]
에어캐나다: [1]
이런식으로 만들어집니다. 나중에 만약 유저가 ‘토론토’로 검색을 한다면 이 역색인을 보고 1,2번 문서를 빠르게 리턴해줄 수 있습니다. 그리고 이를 시간 역순으로 유지하기 위해 트위터는 작성 시각을 사용해서 문서 ID(이후 docId)를 만들었습니다. 27비트는 글이 작성된 시각을 최대값에서 뺀 값으로 만들고, 나머지 4비트는 동일한 시간에 작성된 포스팅을 구분하기 위한 카운터값으로 사용합니다. 식으로 작성한다면 docId = (max_possible_timestamp - current_timestamp) << 4 | counter과 같이 표현됩니다. 27비트로만 시간을 표현하기 때문에 상위 정보값이 사라져서 긴 기간을 저장한다면 충돌이 일어나겠지만, Lucene 자체가 segment별로 나눠서 관리하고 각 segment 안에서만 docId가 고유하면 되기 때문에 상관이 없습니다.
이제 역색인에 대해 파악했으니 저 역색인이 docId를 어떤식으로 저장하는지 알아야합니다. 그리고 이 구조의 개선이 2020년 블로그 포스트에서 말하는 색인에 15초가 걸리던걸 1초로 개선할 수 있었던 주요 포인트입니다.
Skip List의 도입
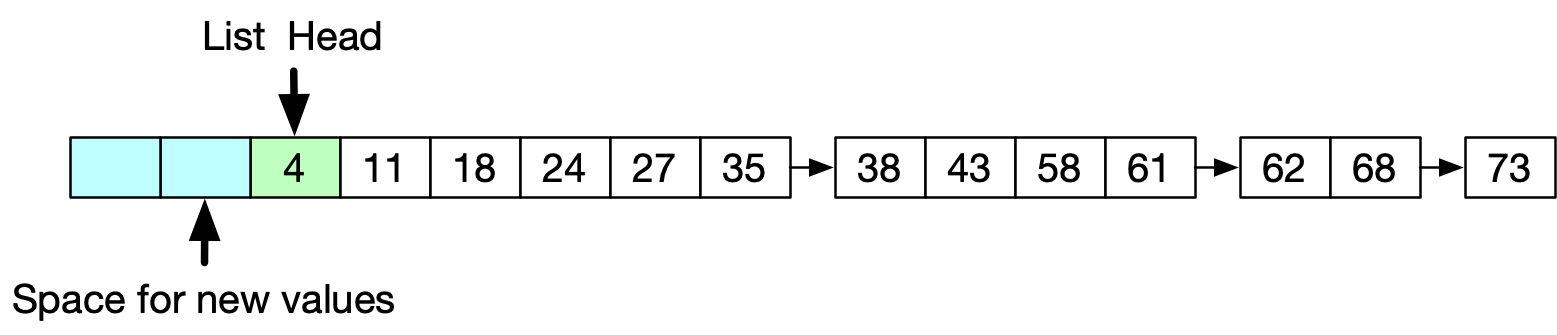
서울특별시: [1,2] 예시에서 [1,2] 처럼 docId를 저장하고 있는 것을 Lucene에서는 posting list라고 부릅니다. 트위터에서는 2020년 이전에는 docId를 Unrolled Linked List로 저장했다고 합니다. 이는 Linked List 중에서도 각 노드가 값 여러 개를 배열로 저장하는 구조입니다. 새로운 값이 항상 Head에 저장되는 방식으로 매우 빠르게(O(1)) 새 노드를 추가할 수 있어 최신 포스팅을 먼저 보여주는 타임라인에 적합하다고 볼 수 있습니다. 하지만 중간에 삽입하는데는 비교적 비용이 많이 들기 때문에, 포스팅이 순서대로 오지 않는다면 적합하지 않은 자료구조였습니다.
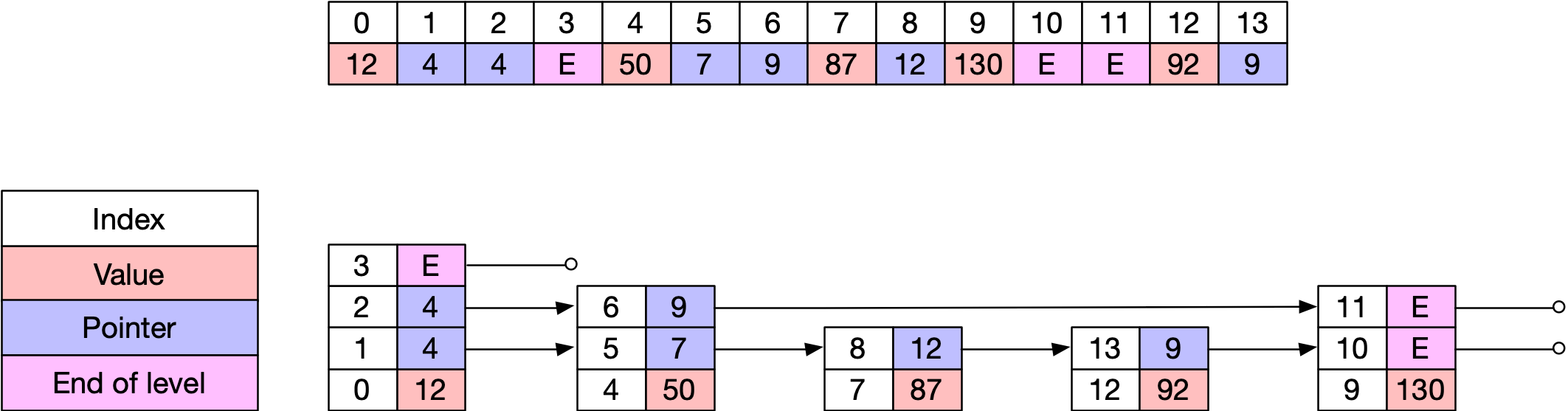
이를 해결하기 위해 Skip list를 도입합니다. Skip List는 O(log n) 삽입/검색이 가능하고 정렬된 데이터에 유연한 장점을 가지고 있습니다. Lucene차원에서도 이 Skip list를 활용하고 있다고 합니다. Skip list는 여러 레벨의 Link List를 관리하는데, 가장 낮은 레벨에는 모든 경우에 삽입을 하고, 높은 레벨일수록 일부 값만 저장을 합니다. 그리고 탐색할 때는 상위 레벨에서부터 빠르게 탐색할 수 있습니다. 트위터에서는 이 Skip list를 도입할 때 이전 탐색 경로를 저장해 반복 탐색 최적화한다든가, primitive array를 사용해 JVM에 오버헤드를 최소화 하는 등의 최적화 작업도 함께 진행했다고 합니다.
순서대로 받진 않지만 원자성은 유지하고 싶어
Skip list를 도입하면서 중간에 노드를 쉽게 삽입할 수 있게 되었습니다. 그런데 이제 원자성을 유지할 수 없다는 문제가 생기게 되었습니다.검색에서 원자성이란 하나의 문서는 모든 인덱싱이 완료되거나 아얘 들어가지 않아야 한다는 것을 뜻합니다. 예를들어 아까의 예시에서 document 2가 인덱싱이 절반만 된 상태에서 원자성이 보장되지 않고 유저가 ‘서울특별시 토론토 -에어캐나다’로 검색했다고 합시다. 유저의 의도는 서울특별시, 토론토에 동시에 인덱싱이 되어 있으면서 에어캐나다에 인덱싱되지는 않은 결과 값을 원할 것입니다. 근데 만약 우리의 document 2의 인덱싱이 진행중이라 서울특별시, 토론토에는 2가 추가되었는데 에어캐나다에는 2가 추가되지 않았다면 유저는 두가지 document를 다 보게 될 것입니다. 유저가 원하던 결과가 아닌 것이지요.
docID가 항상 순서대로 배정됐기 때문에, searcher(검색 쓰레드)는 ‘지금부터 여기까지가 색인 완료된 문서’라는 최소 visible docID를 참조해서 그보다 작은 문서는 아예 건너뛰는 방식을 사용했습니다. 그런데 이제 중간에 삽입이 되니 단순하게 Id만 가지고는 이를 처리할 수 없게 된 것입니다.
이를 해결하기 위해서 docId 대신에 메모리 포인터를 사용했다고 합니다. 리스트라 메모리 위에서 연속적으로 위치하고, 새로운 node는 계속 아래쪽에 추가될 것이기 때문에, published pointer라는 개념을 도입하여 이 pointer보다 밖에 존재한다면 searcher는 해당 문서를 건너뛰게 했습니다.
비동기로 색인하기
이제 중간에 삽입할 준비를 완료했으니, 비동기로 색인을 해볼 수 있습니다. 여기서 비동기로 색인을 하는 것은 외부 서비스에 의존적인 것들입니다. 위에서 소개했듯 포함된 url 같은 것이지요. 혹은 사진이 포함되어있고, 이 사진이 나타내는 keyword도 인덱싱을 하고 싶다면 사진이 첨부된 포스팅도 해당할 것입니다. 여기서는 우리의 document 예시에서 이 티켓을 구매할 수 있는 url이 포함되었다고 가정해보겠습니다:
서울특별시발 토론토행
5월 5일 (월)
편도 · 성인 1명
오전 9:35 – 오전 9:55
대한항공 · 직항 · ICN–YYZ
₩1,137k
http://some.url/xyz
url 말고는 기존과 동일하게 빠르게 인덱싱해서 사람들이 검색할 수 있도록 합니다. 그런데 url을 expand에서 인덱싱하는건 더 시간이 오래 걸립니다. 이는 별도 파이프라인을 타게 됩니다.
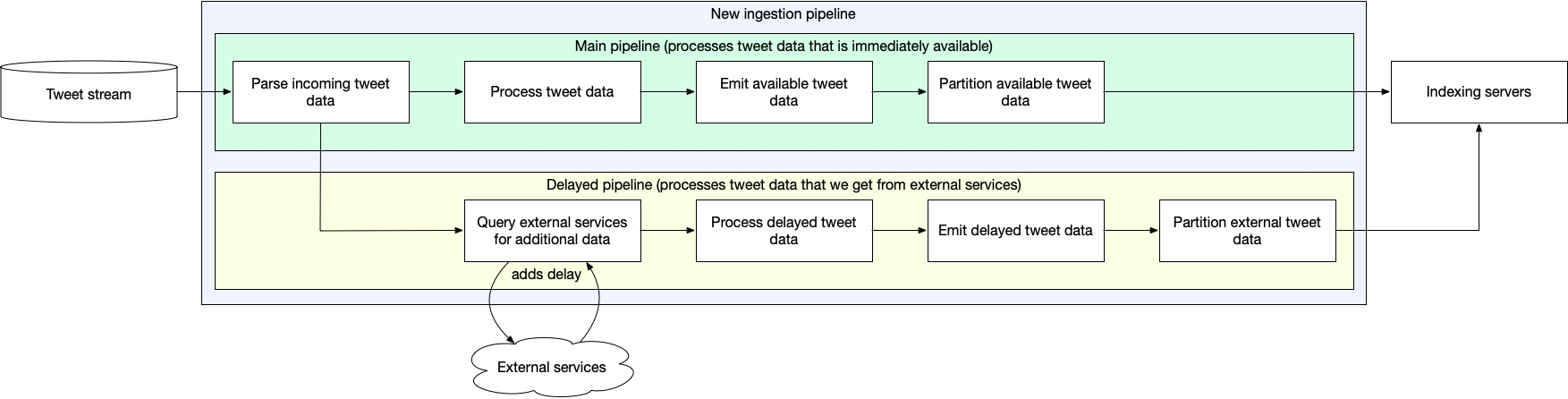
이 url에 대한 정보를 얻고 나면 우리의 posting list에 docId를 추가합니다. 이 부분에서 외부 서비스에 대해서는 원자성이 깨지게 되는데요, 약간의 원자성이 깨지더라도 빠르게 할 수 있는 텍스트에 대해서는 빠르게 인덱싱을 하는게 고객에게 더 나은 경험을 제공할 수 있다고 판단한 것으로 보입니다. (We noticed that most Tweet data that we wanted to index was available as soon as the Tweet was created, and our clients often didn’t need the data in the delayed fields to be present in the index right away.)
‘For You’(추천 타임라인) 구성하기: 데이터의 시작
여기까지가 인덱싱에 관한 블로그 포스팅의 내용이었는데요, 타임라인을 구성하는데 왜이렇게 Indexing 이야기를 오래 했나 생각하셨죠? 그런데 이 인덱싱이 바로 타임라인을 구성하기 위해 필요한 데이터 중 하나이기 때문입니다. 위에서 토론토: [1, 2] 와 같이 keyword만 언급했는데, 사실 author, title, hashtag 같은 필드도 똑같이 인덱싱을 할 수 있다고 합니다. 예를들어 title:"The Right Way" AND go 같은 검색문은 제목은 ‘The Right Way’고 내용에 go를 검색하겠다는건데, 여기서 title도 인덱싱이 되고있다는 것이죠. since, until 등의 검색 방법도 다 동일하게 인덱싱이 기저에 깔려있을 것 같네요.
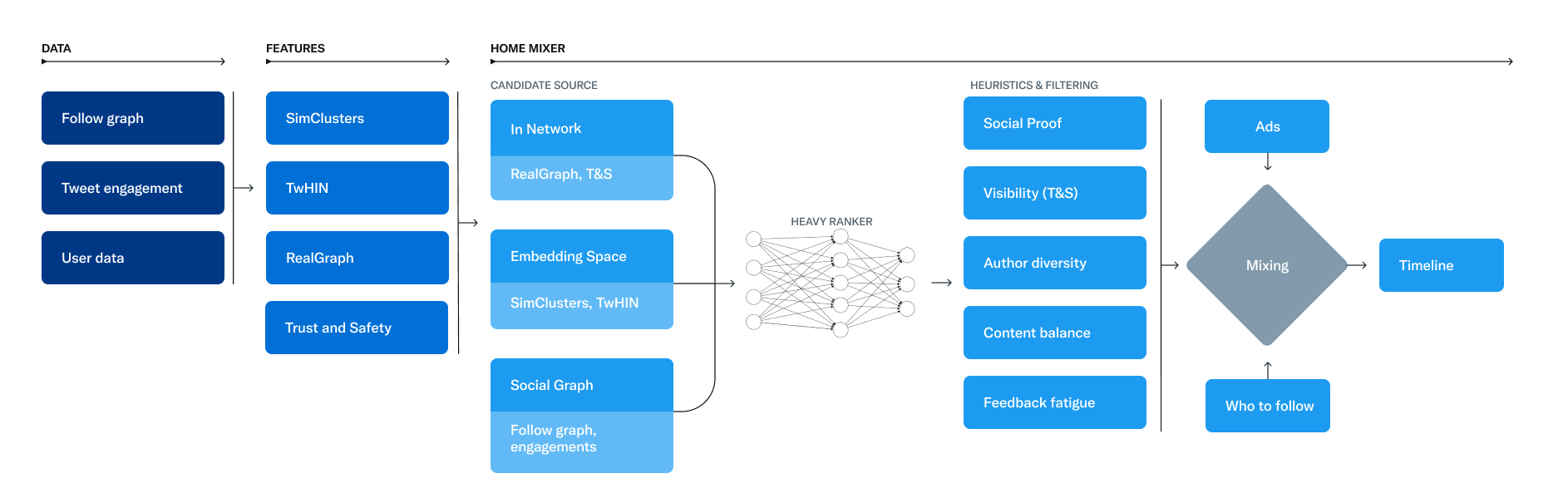
수많은 트윗 중 일부만 사용자의 For You 타임라인에 노출되게 되는데, 이를 위해 추천 알고리즘이 필요하고 추천을 하기 전에 추천 할 후보를 추출해야 합니다. For You 타임라인은 50%는 팔로우 중인 사용자, 나머지 50%는 팔로우 밖의 사용자에서 후보를 추출한다고 합니다. 프론트엔드에서 쿼리를 할 때 local social graph를 넘긴다고 하는데, 이 social graph를 기반으로 팔로하고 있는 사람들이 author인 포스트들을 가져올 것이라고 쉽게 짐작할 수 있습니다.
팔로우 하지 않고 있는 사람들로부터 연관성 있는 포스트 찾기
나머지 50%의 후보는 어떻게 선정할까요? 이에 대해서는 두가지 전략을 취한다고 합니다. 첫번째로는 내가 팔로우하고 있는 사람이 engagement를 한 포스트는 나도 관심이 있을 것이다라는 가정입니다. 이를 위해 유저가 한 좋아요, 리트윗 등의 행위나 비디오 시청, 프로필 확인 등의 행위를 input으로 받습니다.
그림처럼 A2가 B2를 팔로우하고 있고, B2가 C2를 팔로우 한다면, A2에게 C2를 팔로우 하라고 추천을 보낸다고 합니다. 그런데 팔로우 추천 뿐만 아니라 좋아요나 리트윗 등 모든 행위에 대해서 이런 추천 알고리즘을 적용한다는 것이지요.
두번째 방법은 임베딩을 활용하는 것입니다. 이는 LLM이 유행하면서 많은 분들이 익숙한 방식일거라고 생각합니다. 유저의 관심사와 기존 포스팅을 바탕으로 소속되는 커뮤니티를 만들고, 이 커뮤니티를 기반으로 추천을 하는 것입니다.
이 커뮤니티를 만들 때, 먼저 팔로워가 많은 인플루언서들간의 행동을 기반으로 묶어서 그룹을 만들고 다른 유저들을 여기에 배치시키는 방식으로 진행했다고 합니다. 그리고 커뮤니티에 속한 사람들의 반응을 바탕으로 어떤 토픽, 포스트가 이 커뮤니티의 사람들에게 인기가 있는지를 판단해서 추천을 하는 것이죠.
후보 중에서 진짜 ‘당신만을 위한’ 트윗 선별하기
위와 같은 과정을 통해 1500개의 후보가 생긴다고 합니다. 그런데 한번 앱을 켰을 때 그 중에는 많아야 수십개만 노출되죠. 이 노출되는 것은 어떻게 선정할까요? 단순히 모두에게 인기가 많은 것이 선정되는 것이 아니라, ‘내가 관심을 표하고 행동을 할 확률이 높은’ 쪽을 선정한다고 합니다. 여기에는 좋아요, 리트윗, 답글은 물론, ‘첨부된 영상을 50% 이상 볼 확률’, ‘프로필을 확인할 확률’ 같은 것도 포함됩니다. 반대로 부정적인 행위(관심 없음을 표할 것 같다거나, 신고를 할 것 같다거나)를 할 확률도 계산해서 고려합니다. 이를 수행하는 머신 러닝 모델인 Heavy Ranker를 공개하고 있습니다.
이렇게 순위가 선정된 포스트등을 대상으로 다시 조정을 거치게 됩니다. (Heuristic & Filter) 예를들어, 내가 뮤트를 해둔 사람의 글은 빠져야 합니다. 특정 유저의 트윗만 너무 많이 노출되지 않도록 갯수를 조정하기도 합니다. 여기까지 해서 선정된 트윗만이 프론트단으로 전송되고, 프론트는 광고, 팔로우 추천과 같은 컨텐츠와 이를 섞어서 우리의 화면에 보여주게 됩니다.
정리
여기까지 트위터에서 포스트가 작성되고, 인덱싱되어 나중에 타임라인에 구성되기 까지의 흐름을 따라가보았습니다. 여기까지 소개한 것은 일부 뿐으로, 트위터에서 훨씬 많은 종류의 관계 데이터들을 사용하는 것을 알계되었습니다. 예를들어 같은 임베딩이어도 관심사/ 커뮤니티를 기반으로 out-of-network 추천에만 주로 쓰이는 SimClusters와 추천, 검색, 광고 등에 좀 더 범용으로 쓰이는 TwHIN가 있거나 하는 식입니다. 자료구조에서도 Lucene이 skip list를 사용함에도 불구하고 과거에는 삽입에 O(1)이 걸린다는 이점 때문에 Unrolled Linked List를 사용했다가 비동기를 위해 skip list로 이전한 것 같다는 인상을 받았습니다. 모든 기술이 그렇듯이 완벽한 한가지가 있다기 보다는 목적에 맞게, 적재적소에 쓰이는 것이 중요한 것 같습니다.
참고자료
Reducing search indexing latency to one second ElasticSearch에서 사용하는 Apache Lucene의 구조 및 개념 Lucene Package org.apache.lucene.queryparser.classic Analysis of Lucene — Basic Concepts Twitter’s Recommendation Algorithm Earlybird: Real-Time Search at Twitter RealGraph: User Interaction Prediction at Twitter TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation GitHub - the-algorithm GitHub - the-algorithm-ml