
(번역) commits are snapshots, not diffs
원글 : commits are snapshots, not diffs
Git은 혼동을 주는 것으로 유명합니다. 사람들은 용어와 표현들에 있어 혼돈을 많이 겪고 실제와 다른 동작을 상상합니다. 이는 cherry-pick이나 rebase와 같이 기록을 바꾸는 명령에서 특히나 눈에 띄게 보입니다. 제 경험상, 이 혼동은 주로 커밋들을 diff로 이해하는 데서 발생합니다. 하지만, 커밋들은 diff가 아니라 스냅샷 입니다.
Git이 어떻게 여러분의 저장소의 데이터를 저장하는지 원리를 알게 된다면 Git을 더 잘 이해할 수 있습니다. 이 모델을 알아본 후, 새로운 관점이 cherry-pick이나 rebase를 이해하는 데 도움을 주는지 알아보겠습니다.
깊이 이해하고 싶다면, Pro Git의 the Git Internals 장을 읽으면 됩니다.
예시로 v2.29.2에서 check out 한 git 저장소를 사용하겠습니다. 추가적인 연습을 위해 제 커맨드라인 예시들을 따라오세요.
Object ID는 해시다
Git object를 이해하는데 있어서 가장 중요한 것은 git은 각 object를 고유한 값의 object ID(OID)를 이용해 참조한다는 것입니다. 우리는 git rev-parse <ref> 명령을 사용해 이 OID들을 볼 수 있습니다. 각 객체는 기본적으로 plain-text 파일이고 내용은 git cat-file -p <oid>명령으로 읽습니다.
여러분은 OID들을 더 짧은 hex 문자열로 보는 것에 더 익숙할 수 있습니다. 이 문자열은 저장소 안에서 이 object를 특정할 수 있는 길이를 가집니다. 만약 특정할 수 없다면, 일치하는 OID들의 목록을 보여줍니다.
$ git cat-file -t e0c03
error: short SHA1 e0c03 is ambiguous
hint: The candidates are:
hint:
(중략)
blob, tree, commit… 얘네는 무엇일까요? 가장 아래의 기초부터 살펴봅시다.
Blob은 파일 내용이다
object 모델에 있어서 blob은 파일 내용을 가지고 있습니다. 현재 revision에서의 OID를 알아내기 위해 git rev-parse HEAD:<path>를 실행한 후 git cat-file -p <oid>로 내용물을 확인하도록 합니다.
$ git rev-parse HEAD:README.md
eb8115e6b04814f0c37146bbe3dbc35f3e8992e0
$ git cat-file -p eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 | head -n 8
[](https://github.com/git/git/actions?query=branch%3Amaster+event%3Apush)
Git - fast, scalable, distributed revision control system
=========================================================
Git is a fast, scalable, distributed revision control system with an
unusually rich command set that provides both high-level operations
and full access to internals.
README.md를 수정하게 되면 git status가 파일이 최근 수정된 시간을 인식하고 내용을 해싱합니다. 만약 내용이 HEAD:README.md의 현재 OID와 일치하지 않는다면 git status는 파일이 “디스크에서 수정되었다. modified on disk.”고 알려줍니다. 이로 인해 우리는 현재 working directory의 파일 내용이 HEAD의 내용과 일치하는지 확인할 수 있습니다.
Trees are directory listings
blob은 파일의 내용은 가지고 있지만, 파일의 이름은 가지고 있지 않습니다. 파일명은 Git이 폴더를 표현하는 tree에 있습니다. tree는 path entry들의 ordered list이고 object type, file mode, 그리고 해당 경로에 존재하는 object들의 OID를 가지고 있습니다. 서브디렉토리도 tree로 표현되기 때문에 tree들은 다른 tree를 가리킬 수 있습니다.
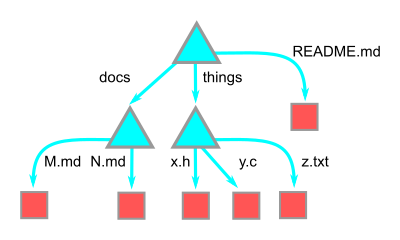
시각화해보면 그림에서 상자가 blob들이고 삼각형이 tree들입니다.
$ git rev-parse HEAD^{tree}
75130889f941eceb57c6ceb95c6f28dfc83b609c
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | head -n 15
100644 blob c2f5fe385af1bbc161f6c010bdcf0048ab6671ed .cirrus.yml
100644 blob c592dda681fecfaa6bf64fb3f539eafaf4123ed8 .clang-format
100644 blob f9d819623d832113014dd5d5366e8ee44ac9666a .editorconfig
100644 blob b08a1416d86012134f823fe51443f498f4911909 .gitattributes
040000 tree fbe854556a4ae3d5897e7b92a3eb8636bb08f031 .github
100644 blob 6232d339247fae5fdaeffed77ae0bbe4176ab2de .gitignore
100644 blob cbeebdab7a5e2c6afec338c3534930f569c90f63 .gitmodules
100644 blob bde7aba756ea74c3af562874ab5c81a829e43c83 .mailmap
100644 blob 05f3e3f8d79117c1d32bf5e433d0fd49de93125c .travis.yml
100644 blob 5ba86d68459e61f87dae1332c7f2402860b4280c .tsan-suppressions
100644 blob fc4645d5c08bd005238fc72cfa709495d8722e6a CODE_OF_CONDUCT.md
100644 blob 536e55524db72bd2acf175208aef4f3dfc148d42 COPYING
040000 tree a58410edddbdd133cca6b3322bebe4fb37be93fa Documentation
100755 blob ca6ccb49866c595c80718d167e40cfad1ee7f376 GIT-VERSION-GEN
100644 blob 9ba33e6a141a3906eb707dd11d1af4b0f8191a55 INSTALL
Tree들은 각 sub-item들의 이름을 가지고 있습니다. 또한 유닉스의 파일 퍼미션이나 object type(blob인지 tree인지) 그리고 각 entry의 OID를 가지고 있습니다. 위 예시에서는 최상위 15개 entry에서 잘랐지만 grep을 사용하면 이 tree가 위의 blob OID를 가리키는 README.md entry를 가지고 있다는 것을 알 수 있습니다.
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | grep README.md
100644 blob eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 README.md
Tree는 이 path entry들을 사용해 blob이나 다른 tree를 가리킬 수 있습니다. 그림에 매번 표시하지 않더라도 관계는 이런 관계는 path name들과 짝을 이루고 있다는 것을 기억하세요.
tree 자체로는 저장소 안에서 어디에 존재하는지 알지 못합니다. 이는 tree를 가리키는 object의 역할입니다. <ref>^{tree}가 가리키는 tree는 특별한 tree - root tree - 입니다. 이는 여러분의 커밋에서 만들어지는 특별한 링크에 의해 지정됩니다.
Commits are snapshots
커밋은 특정 시간의 snapshot입니다. 각 커밋은 각자의 root tree를 가리키는 포인터를 가지고 있고 이는 당시의 working directory의 상태를 나타냅니다. 커밋은 부모 커밋의 리스트들을 가지고 있고 이는 이전 snapshot들입니다. 부모가 없는 커밋은 root 커밋이고 복수의 부모가 있는 커밋은 merge 커밋입니다. 또한, 커밋은 snapshot의 author나 committer, 커밋 메시지 등을 담은 metadata도 가지고 있습니다. 커밋 메시지는 commit 저자에게 commit의 목적을 설명할 기회입니다. (with respect to the parents)
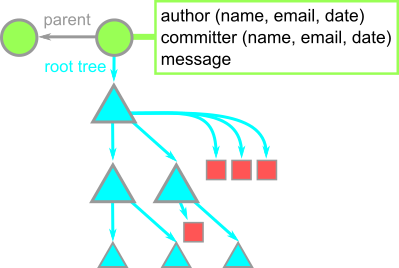
예를 들어, Git 저장소의 v2.29.2에서의 커밋은 해당 릴리즈를 설명하고 Git maintainer에 의해 쓰이고 커밋되었습니다.
$ git rev-parse HEAD
898f80736c75878acc02dc55672317fcc0e0a5a6
/c/_git/git ((v2.29.2))
$ git cat-file -p 898f80736c75878acc02dc55672317fcc0e0a5a6
tree 75130889f941eceb57c6ceb95c6f28dfc83b609c
parent a94bce62b99be35f2ee2b4c98f97c222e7dd9d82
author Junio C Hamano <gitster@pobox.com> 1604006649 -0700
committer Junio C Hamano <gitster@pobox.com> 1604006649 -0700
Git 2.29.2
Signed-off-by: Junio C Hamano <gitster@pobox.com>
git log를 이용해 이력을 좀 더 살펴보면 우리는 부모 커밋과 해당 커밋의 차이를 설명하는 더 자세한 커밋 메시지를 볼 수 있습니다.
$ git cat-file -p 16b0bb99eac5ebd02a5dcabdff2cfc390e9d92ef
tree d0e42501b1cf65395e91e22e74f75fc5caa0286e
parent 56706dba33f5d4457395c651cf1cd033c6c03c7a
author Jeff King <peff@peff.net> 1603436979 -0400
committer Junio C Hamano <gitster@pobox.com> 1603466719 -0700
am: fix broken email with --committer-date-is-author-date
Commit e8cbe2118a (am: stop exporting GIT_COMMITTER_DATE, 2020-08-17)
rewrote the code for setting the committer date to use fmt_ident(),
rather than setting an environment variable and letting commit_tree()
handle it. But it introduced two bugs:
- we use the author email string instead of the committer email
- when parsing the committer ident, we used the wrong variable to
compute the length of the email, resulting in it always being a
zero-length string
This commit fixes both, which causes our test of this option via the
rebase "apply" backend to now succeed.
Signed-off-by: Jeff King <peff@peff.net> Signed-off-by: Junio C Hamano <gitster@pobox.com>
우리 그림에서 동그라미로 커밋들을 나타내겠습니다. 정리하면: 상자는 blob. file 내용을 나타냅니다 세모는 tree. directory를 나타냅니다. 동그라미는 commit. 시간의 shapshot입니다.
branches are pointers
Git에서 대부분의 시간 동안은 OID를 신경 쓰지 않고 history를 돌아다니거나 변경합니다. 이는 branch 들이 우리가 신경 쓰는 commit을 가리키는 포인터를 제공하기 때문입니다. main이라는 이름의 브랜치는 사실 Git 안의 refs/heads/main을 참조합니다. 이 파일들은 커밋의 OID를 가르키는 헥사 문자열을 가지고 있습니다. 당신이 작업하면 이 참조 값이 다른 커밋으로 값을 바꾸게 됩니다.
이는 브랜치가 우리의 기존 Git 오브젝트와 전혀 다르다는 것을 의미합니다. Commits, trees 그리고 blobs는 변경되지 않습니다. 당신이 작업물을 수정하면 새로운 object를 가리키는 새 hash값과 새 OID를 얻게 될 것입니다. 브랜치는 의미를 가지기 위해 사용자가 이름을 짓게 됩니다. 예를 들어 trunk나 my-special-project와 같은 것이죠. 우리는 작업을 추적하고 공유하기 위해 브랜치를 사용합니다.
특별 참조 HEAD는 현재 브랜치를 가리킵니다. 우리가 HEAD에 커밋을 쌓으면 자동으로 현재 브랜치에 새로운 커밋을 업데이트합니다.
우리는 git switch -c를 통해 새로운 브랜치를 만들면서 HEAD를 업데이트 할 수 있습니다.
$ git switch -c my-branch
Switched to a new branch 'my-branch'
$ cat .git/refs/heads/my-branch
1ec19b7757a1acb11332f06e8e812b505490afc6
$ cat .git/HEAD
ref: refs/heads/my-branch
my-branch를 만드는 것이 현재 커맷 OID를 가진 파일(.git/refs/heads/my-branch)을 만들고 .git/HEAD 파일의 포인터가 이 브랜치로 업데이트된 것을 확인하세요. 이제, 우리가 새로운 커밋을 만들어 HEAD 값을 업데이트하면 my-branch 브랜치가 새로운 커밋으로 포인터를 업데이트 할 것입니다.
The big picture
개념들을 그림 하나로 모두 정리해보겠습니다. 브랜치들은 커밋을 가리키고 커밋들은 다른 커밋을 가리키거나 root trees를 가리킵니다. tree들은 blobs나 다른 트리를 가리키고 blob은 아무것도 가리키지 않습니다. 아래 그림은 모든 개념을 포함한 그림입니다.
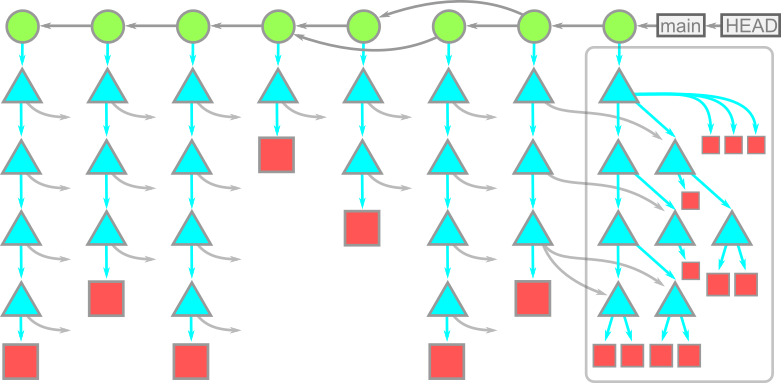
이 그림에서 시간은 왼쪽에서 오른쪽으로 흐릅니다. 커밋들간에는 화살표가 있고 오른쪽에서 왼쪽으로 갈수록 부모 커밋입니다. 각 커밋들은 한 개의 root tree를 가집니다. HEAD는 main 브랜치를 가리키고 있고 main은 가장 최신 커밋을 가리키고 있습니다. 이 커밋의 root tree는 아래로 완전히 확장되어 있고 다른 tree에서 이 object들을 가리키는 화살표가 있습니다. 왜냐하면 여러 개의 root tree들이 같은 object에 접근할 수 있기 때문입니다. tree들은 OID(내용)을 통해 object에 접근하기 때문에 이 스냅샷들은 같은 내용에 대해 여러 개의 복사본을 만들어 둘 필요가 없습니다. 이런 방식을 통해 깃의 오브젝트 모델은 Merkle tree를 이룹니다.
우리가 이런 방식으로 오브젝트 모델을 바라볼 때 왜 커밋들이 스냅샷인지 알 수 있습니다 : 커밋들은 해당 커밋의 working directory에 직접적으로 연결되어 있습니다.
computing diffs
커밋이 스냅샷이라고 하더라도 우리는 커밋을 history view나 깃허브에서 diff로서 바라보곤 합니다. 사실, 커밋 메세지도 이 변경 사항에 대해 서술하곤 하죠. diff는 스냅샷 데이터의 root tree와 그 부모를 비교해서 동적으로 생성됩니다. Git은 이웃한 커밋이 아니더라도 두 개의 스냅샷을 바로 비교할 수 있습니다. 이 두 커밋을 비교하기 위해 그들의 root tree부터 살펴보겠습니다. 이들은 거의 항상 다르지요. 하위 tree에 대해 깊이 우선 탐색을 수행하여 서로 다른 OID를 가진 경로의 쌍을 찾아냅니다. 아래 예시에서 각 tree는 서로 다른 docs 값을 가지고 있습니다. 따라서 우리는 두 doc 트리의 값을 재귀적으로 검사합니다. 두 doc 트리는 서로 다른 M.md 값을 가지고 있음으로 두 (M.md) blob를 한줄 한줄씩 비교해 변경사항을 보여줍니다. 같은 docs 안에서도 M.md값은 동일하므로 스킵하고 root tree로 돌아옵니다. 그러면 root tree는 things 디렉터리와 REAME.md엔트리의 OID가 같다는 것을 확인할 것입니다.
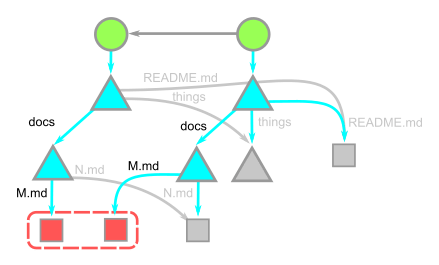
위 그림에서 things 트리는 방문하지 않았습니다. 따라서 things에 연결된 object도 방문하지 않았습니다. 즉, diff를 계산하는 비용은 수정이 일어난 경로의 수에 비례합니다.
이제 우리는 커밋이 스냅샷이다 라는 것을 이해했고 어느 커밋이든 둘의 diff를 계산할 수 있습니다. 그럼 왜 이게 상식이 아닌 걸까요? 왜 새로운 사용자들이 커밋이 diff라고 착각하는 실수를 저지를까요?
제가 가장 좋아하는 해석은 커밋이 파동-입자 이중성을 가지고 있다는 것입니다. 어떨 때는 스냅샷처럼 취급되는데 다른 때에는 diff처럼 취급된다는 것이지요. 이 점은 사실 Git object가 아니라 새로운 종류의 데이터인 patch와 연결됩니다.
Wait, what’s a patch?
patch는 기존 codebase를 어떻게 변경해야 하는지를 담은 텍스트 문서입니다. Patch는 분산된 그룹이 Git 커밋을 직접 통하지 않고 코드를 공유하는 방법이지요. Git mailing list에서도 이것들이 돌아다니는 것을 볼 수 있습니다.
patch는 변경 사항과 변경 사항에 대한 설명, 그리고 왜 이것이 필요한지에 대한 설명을 가지고 있습니다. 그 설명으로 자신의 코드에 해당 변경 사항을 적용 하는 것을 합리화한다는 아이디어입니다.
git format-patch를 이용해 커밋을 패치로 변환할 수 있고 git apply를 사용해 패치를 깃 저장소에 반영할 수 있습니다. 이것은 초기 오픈 소스에 있어서 일반적으로 코드를 공유하는 방법이었습니다. 하지만 대부분의 프로젝트는 이제 pull request를 통해 직접 git commit을 공유하는 방식으로 변경되었습니다.
patch를 공유하는 것의 가장 큰 문제점은 patch는 부모에 대한 정보를 가지고 있지 않아 당신이 가지고 있는 HEAD를 부모로 삼는다는 것입니다. 게다가 커밋 시간의 차이 때문에 같은 부모를 가지고 있을지라도 다른 커밋을 가지게 되고 커미터가 바뀌게 됩니다. 이것이 Git이 commit 오브젝트 안에 저자(author)와 커미터(commiter) 필드를 둘 다 가지고 있는 근본적인 이유입니다.
patch를 사용하는 것의 가장 큰 문제점은 당신의 working directory가 보낸 이의 previous commit과 일치하지 않을 때 패치를 적용하기 힘들다는 점에 있습니다. 커밋 히스토리를 잃어버린다는 점에서 conflict를 해결하기 어렵습니다.
“패치를 주고받는다.”라는 아이디어는 “커밋을 주고받는다(옮긴다).”라는 개념으로서 몇개의 Git 커맨드로 들어왔습니다. 대신 실제로 일어나는 일은 커밋 변경 사항들이 다시 수행되어 새로운 커밋을 만들어내는 것 입니다.
커밋이 diff가 아니라면 git cherry-pick은 어떤 일을 하나요?
git cherry-pick <oid> 커맨드는 현재 커밋을 부모로 갖는 <oid>와 동일한 커밋을 만들어 냅니다. 깃은 기본적으로 아래 과정을 수행합니다.
<oid>커밋과<oid>의 부모커밋의 변경 사항을 구합니다.- 현재 HEAD에 위에서 구한 변경 사항을 적용합니다.
- root tree가 새 working directory와 일치하고 부모가
HEAD인 새 커밋을 만듭니다. HEAD의 참조값을 위에서 만든 새 커밋으로 바꿉니다.
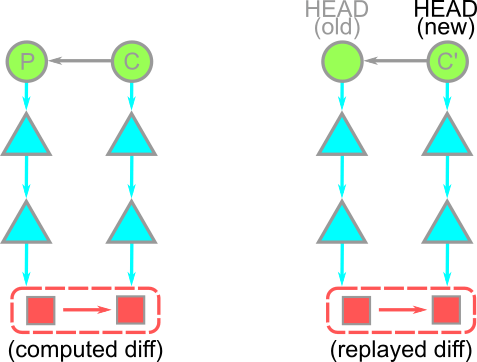
깃이 새로운 커밋을 만든 후 git log -1 -p HEAD의 출력값은 git log -1 -p <oid> 출력값과 동일해야 합니다.
우리가 커밋을 HEAD의 위로 “이동”시킨 게 아니라 변경 사항이 동일한 새 커밋을 만들었다 는 것을 깨닫는 것이 중요합니다.
커밋이 diff가 아니라면 git rebase는 어떤 일을 하나요
git rebase는 커밋이 새로운 이력을 가지기 위해 이동되는 것으로 설명됩니다. 기본적으로 이는 git cherry-pick 커맨드의 반복입니다. 다른 커밋 위에 변경 사항을 되풀이하며 쌓는 것이죠.
가장 중요한게는 git rebase <target>은 HEAD와는 연결되어 있지만 <target>과는 이어져 있지 않은 커밋들의 리스트를 만듭니다. git log --oneline <target>..HEAD를 이용하여 이 목록을 직접 볼 수 있습니다.
그 후 rebase 커맨드는 <target>의 위치로 가서 가장 오래된 커밋부터 범위에 해당하는 커밋들에 대해 git cherry-pick 커맨드를 수행하기 시작합니다. 마지막에는 다른 OID를 가지지만 비슷한 수정 항목을 가진 커밋들을 가지게 되겠지요.
예를 들어, <target>과 분기 된 이후에 세 개의 커밋이 쌓인 HEAD가 있다면 git rebase <target>을 실행시켰을 때 공통 베이스인 p를 계산해 커밋 리스트 A, B, C를 얻게 될 것입니다. 그 이후 <target>위에 cherry-pick으로 올려 새로운 커밋 A', B', C'를 만들게 됩니다.
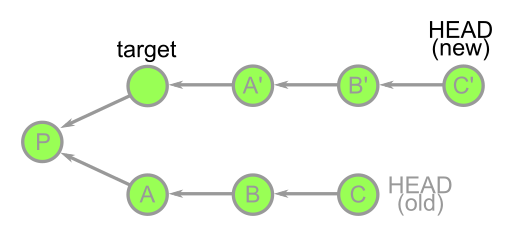
커밋 A', B', C'는 A, B, C와 아주 비슷하지만, 분명히 구분되는 새 오브젝트입니다. 사실, 이전 커밋들도 가비지 컬렉션이 진행되기 전까지는 당신의 저장소에 남아있습니다.
우리는 심지어 이 두 커밋 범위가 다른지 git range-diff 커맨드를 이용해서 확인할 수 있습니다. Git repository에서 예시 커밋들을 v2.29.2 태그 위에 리베이스 하고 가장 상위 커밋을 조금 수정해보겠습니다.
$ git checkout -f 8e86cf65816
$ git rebase v2.29.2
$ echo extra line >>README.md
$ git commit -a --amend -m "replaced commit message"
$ git range-diff v2.29.2 8e86cf65816 HEAD
1: 17e7dbbcbc = 1: 2aa8919906 sideband: avoid reporting incomplete sideband messages
2: 8e86cf6581 ! 2: e08fff1d8b sideband: report unhandled incomplete sideband messages as bugs
@@ Metadata
Author: Johannes Schindelin <Johannes.Schindelin@gmx.de>
## Commit message ##
- sideband: report unhandled incomplete sideband messages as bugs
+ replaced commit message
- It was pretty tricky to verify that incomplete sideband messages are
- handled correctly by the `recv_sideband()`/`demultiplex_sideband()`
- code: they have to be flushed out at the end of the loop in
- `recv_sideband()`, but the actual flushing is done by the
- `demultiplex_sideband()` function (which therefore has to know somehow
- that the loop will be done after it returns).
-
- To catch future bugs where incomplete sideband messages might not be
- shown by mistake, let's catch that condition and report a bug.
-
- Signed-off-by: Johannes Schindelin <johannes.schindelin@gmx.de>
- Signed-off-by: Junio C Hamano <gitster@pobox.com>
+ ## README.md ##
+@@ README.md: and the name as (depending on your mood):
+ [Documentation/giteveryday.txt]: Documentation/giteveryday.txt
+ [Documentation/gitcvs-migration.txt]: Documentation/gitcvs-migration.txt
+ [Documentation/SubmittingPatches]: Documentation/SubmittingPatches
++extra line
## pkt-line.c ##
@@ pkt-line.c: int recv_sideband(const char *me, int in_stream, int out)
range-diff의 결과가 커밋 17e7dbbcbc와 2aa8919906이 “동일”하다고 하는 것을 확인하세요. 즉 이 둘은 같은 patch를 생성할 것입니다. 두 번째 커밋 짝은 다릅니다. 커밋 메시지가 바뀌었고 원래 커밋에는 없던 변경 사항이 README.md에 생겼습니다.
여기까지 따라왔다면 이 두 개 커밋 세트에 대해 이력이 어떻게 존재하는지도 알 수 있습니다. 새로운 커밋은 v2.29.2 태그를 이력의 세 번째 커밋으로 가지고 있지만, 이전 커밋은 v2.29.0 태그를 세 번째 커밋으로 가지고 있습니다.
$ git log --oneline -3 HEAD
e08fff1d8b2 (HEAD) replaced commit message
2aa89199065 sideband: avoid reporting incomplete sideband messages
898f80736c7 (tag: v2.29.2) Git 2.29.2
$ git log --oneline -3 8e86cf65816
8e86cf65816 sideband: report unhandled incomplete sideband messages as bugs
17e7dbbcbce sideband: avoid reporting incomplete sideband messages
47ae905ffb9 (tag: v2.28.0) Git 2.28
커밋이 diff가 아니라면, Git은 어떻게 rename을 추적하나요?
오브젝트 모델을 잘 관찰해왔다면 Git이 변경사항들을 전혀 저장하지 않는다는 것을 알았을 것입니다. 그렇다면 “깃이 어떻게 파일명이 바뀌었다는 것을 알까”하고 궁금했을 것입니다.
Git은 파일명 변경을 추적하지 않습니다. Git 안에는 부모와 현재 커밋 사이에 파일명이 바뀌었는지를 저장할만한 자료 구조가 없습니다. 대신, 깃은 동적으로 diff를 계산할 때 파일명 변경을 감지하려고 합니다. 파일명을 감지할 때는 두 단계를 거칩니다 : exact rename과 edit-rename입니다.
diff를 계산한 후 깃은 변경 사항들의 내부 모델을 보고 어떤 경로가 더해졌거나 지워졌는지를 확인합니다. 기본적으로 파일이 이동되었다면 이전 경로에서는 삭제되었고 새 위치에서 추가된(add) 것으로 보일 것입니다. 깃은 이 삭제된 것과 추가된 것들을 매치시켜서 파일명 변경을 추론합니다.
이 매치하는 작업은 먼저 경로에서 추가/삭제된 OID들을 보고 그들 중 정확히 동일한 짝이 있는지를 알아냅니다. 이 짝들이 묶이게 됩니다. 그다음으로는 시간이 많이 드는 부분입니다 : 파일명이 변경되면서 수정도 같이 된 경우는 어떻게 알아낼까요? 깃은 추가된 파일들 하나하나를 삭제된 파일들과 비교하며 공통된 행 수가 전체의 몇 퍼센트인지로 ‘유사도 점수’를 계산합니다. 기본적으로 50% 이상이라면 수정과 파일명 변경이 동시에 일어난 경우일 수 있다고 생각합니다. 가장 유사도가 높은 짝을 찾을 때까지 둘씩 비교하게 됩니다.
문제점을 발견하셨나요? 이 알고리즘은 A가 추가된 파일 수고 D가 삭제된 파일 수일 때 A * D번 비교 합니다. 이차식인 거죠! 과도하게 긴 rename 계산을 막기 위해 A + D가 내부 일정 값 이상이라면 이 계산을 하지 않습니다. 이 값은 diff.renameLimit 설정값에서 변경할 수 있습니다. 또한 이 모든 알고리즘은 diff.rename 옵션을 끄면 피할 수 있습니다.
나는 개인 프로젝트에서 깃의 파일명 수정 감지 기능에 대한 지식을 사용해왔습니다. 예를 들어, 저는 VFS for Git을 포크해 Scalar 프로젝트를 만들면서 많은 코드를 재사용하고자 했으나 동시에 파일 구조를 많이 바꾸고 싶었습니다. VFS for Git 코드 베이스의 이력도 따라가고 싶었기 때문에 리팩토링을 두 단계에 걸쳐서 진행했습니다.
이 두 과정을 통해 git log --follow --<path>를 사용했을 때 파일명이 변경되었음에도 이력들을 볼 수 있습니다.
$ git log --oneline --follow -- Scalar/CommandLine/ScalarVerb.cs
4183579d console: remove progress spinners from all commands
5910f26c ScalarVerb: extract Git version check
...
9f402b5a Re-insert some important instances of GVFS
90e8c1bd [REPLACE] Replace old name in all files
fb3a2a36 [RENAME] Rename all files
cedeeaa3 Remove dead GVFSLock and GitStatusCache code
a67ca851 Remove more dead hooks code
...
중간에 생략되었지만 마지막 두 커밋은 Scarlar/CommandLine/ScalarVerb.cs에 해당하는 경로를 가지고 있지 않습니다. 대신 이전 경로인 GVFS/GVFS/CommandLine/GVFSVerb.cs의 이력을 따라갑니다. 왜냐면 깃이 파일명만 바꾼 커밋인 fb3a2a36 [RENAME] Rename all files를 인식하고 있기 때문입니다.
이제 헷갈리지 마세요!
이제 여러분은 커밋은 diff가 아니라 스냅샷 이라는 것을 알았습니다. 이 이해는 Git을 사용하며 일할 때 지표가 되어줄 것입니다.
이제 여러분은 깃 오브젝트 모델에 대한 깊은 이해로 무장했습니다. 이 지식을 깃 커맨드를 쓰는 데 사용하거나 여러분의 팀의 워크 플로우를 결정할 때 사용할 수 있을 것입니다. 차후 블로그 포스트에서 여러 Git clone 옵션과 문제를 해결하기 위한 데이터를 줄이는 방법을 알아보도록 하겠습니다.